

Machine Learning Techniques for Speech Emotion Recognition

Search for a command to run...
No comments yet. Be the first to comment.
I've been working with high-dimensional data for sometime now, and the question I get asked most often isn't about neural networks or gradient boosting. It's some variation of "my model is slow and I

Integrating your backend systems with Slack can significantly improve your team's operational awareness through automated notifications. This guide walks through the complete process of setting up a S

Installing Conda on EC2 Look, installing Conda on EC2 doesn't need to be complicated. After setting this up across hundreds of instances, here's my approach that just works. The Fast Track Skip the fl

FastAPI has gained significant traction among developers for its high performance and ease of use in building APIs. When it comes to deploying FastAPI applications, several hosting options are available, including Heroku, Google Cloud Run, DigitalOce...

Learn how to set up, install, and optimize GPU-enabled instances for high-performance computing, machine learning, and graphics-intensive workloads in the AWS cloud. Ideal for system administrators, DevOps engineers, and cloud architects looking to h...

Speech emotion recognition (SER) is the task of automatically identifying the emotional state of a speaker from their voice. It has important applications in areas like human-computer interaction, call centers, healthcare, and affective computing. Over the past decade, deep learning approaches have led to significant advances in SER performance compared to traditional machine learning methods. This article provides a comprehensive overview of deep learning techniques for SER, comparing them to traditional approaches, and discussing the latest state-of-the-art methods.
Conventional SER systems typically follow a pipeline of:
Feature extraction from speech signal
Feature selection/dimensionality reduction
Classification using machine learning algorithms
The most commonly used acoustic features include:
Prosodic features: Fundamental frequency (F0), energy, speaking rate
Voice quality features: Jitter, shimmer, harmonic-to-noise ratio
Spectral features: Mel-frequency cepstral coefficients (MFCCs), formants
Teager energy operator (TEO) based features
For classification, popular algorithms include Support Vector Machines (SVM), Hidden Markov Models (HMM), Gaussian Mixture Models (GMM), and k-Nearest Neighbors (kNN).
While these traditional approaches achieved reasonable performance, they have several limitations:
Hand-crafted features may not capture all relevant emotional information
Feature engineering requires domain expertise
Shallow classifiers have limited modeling capacity
Difficulty in handling contextual information and long-range dependencies
The advent of deep learning has transformed the SER landscape. Deep neural networks can automatically learn hierarchical representations from raw speech signals or low-level acoustic features. This eliminates the need for manual feature engineering. The high modeling capacity of deep networks allows them to capture complex emotional patterns in speech. Some key advantages of deep learning for SER include:
Automatic feature learning from raw speech
Better modeling of contextual information
Ability to handle large-scale datasets
End-to-end training
Common deep learning architectures used for SER include:
Convolutional Neural Networks (CNNs)
Recurrent Neural Networks (RNNs) - LSTM, GRU
Hybrid CNN-RNN models
Attention mechanisms
Transformer networks
Generative models - VAEs, GANs
Let's look at how these architectures are applied to SER in more detail.
CNNs are effective at capturing local patterns and spectro-temporal features in speech. A typical CNN architecture for SER consists of:
Convolutional layers to extract features
Pooling layers for downsampling
Fully connected layers for classification
The input is usually a 2D time-frequency representation like a spectrogram or mel-spectrogram. Multiple convolutional kernels scan across the input to detect relevant patterns at different scales.
Here's a simple CNN architecture for SER in Python using Keras:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten
model = Sequential([
Conv2D(32, (3,3), activation='relu', input_shape=(128, 128, 1)),
MaxPooling2D((2,2)),
Conv2D(64, (3,3), activation='relu'),
MaxPooling2D((2,2)),
Conv2D(64, (3,3), activation='relu'),
Flatten(),
Dense(64, activation='relu'),
Dense(7, activation='softmax') # 7 emotion classes
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
RNNs, especially LSTM and GRU variants, are well-suited for modeling sequential data like speech. They can capture long-term dependencies and contextual information. A basic RNN architecture for SER looks like:
from tensorflow.keras.layers import LSTM, Dense
from tensorflow.keras.models import Sequential
model = Sequential([
LSTM(128, return_sequences=True, input_shape=(None, 13)), # 13 MFCC features
LSTM(64),
Dense(32, activation='relu'),
Dense(7, activation='softmax') # 7 emotion classes
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Combining CNNs and RNNs leverages the strengths of both architectures. CNNs extract local spectro-temporal features, while RNNs model long-term dependencies. A common approach is to use CNNs for feature extraction followed by RNNs for sequence modeling.
from tensorflow.keras.layers import Conv2D, MaxPooling2D, LSTM, Dense, Reshape
from tensorflow.keras.models import Sequential
model = Sequential([
Conv2D(32, (3,3), activation='relu', input_shape=(128, 128, 1)),
MaxPooling2D((2,2)),
Conv2D(64, (3,3), activation='relu'),
MaxPooling2D((2,2)),
Reshape((-1, 64*30*30)), # Flatten CNN output for LSTM
LSTM(64, return_sequences=True),
LSTM(32),
Dense(7, activation='softmax')
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Attention allows the model to focus on the most relevant parts of the input sequence for emotion recognition. It has been successfully applied to SER, often in combination with RNNs or CNNs. Self-attention, as used in Transformer models, has also shown promising results.
Transformer architectures, which rely entirely on attention mechanisms, have achieved state-of-the-art performance in many speech and NLP tasks. For SER, Transformers can effectively capture long-range dependencies and parallelized computations. Pre-trained speech Transformers like Wav2Vec 2.0 have been fine-tuned for SER with impressive results.
Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) have been explored for SER. These models can learn disentangled representations of emotion and speaker identity, which is useful for speaker-independent SER. They can also generate synthetic emotional speech data for augmentation.
Several studies have compared deep learning methods to traditional machine learning approaches for SER. The general consensus is that deep learning outperforms conventional techniques, especially on larger datasets. Here's a summary of key findings:
Feature Learning: Deep models can learn more discriminative features compared to hand-crafted acoustic features.
Contextual Modeling: RNNs and attention mechanisms capture long-term dependencies better than frame-level classifiers like SVM.
Generalization: Deep models often generalize better to unseen speakers and recording conditions.
Scalability: Deep learning leverages large datasets more effectively, showing consistent improvement with more data.
Multimodal Fusion: Deep architectures excel at fusing multiple modalities (e.g., speech + text) for emotion recognition.
End-to-end Learning: Deep models can be trained end-to-end, optimizing feature extraction and classification jointly.
Transfer Learning: Pre-trained deep models can be fine-tuned for SER, benefiting from knowledge transfer.
However, traditional approaches still have some advantages:
Interpretability: Hand-crafted features are more interpretable than learned representations.
Data Efficiency: Traditional methods may perform better with very small datasets.
Computational Efficiency: Shallow models are generally faster to train and deploy.
Domain Knowledge: Traditional approaches can incorporate valuable domain expertise.
Recent advances in deep learning have pushed the boundaries of SER performance. Here are some state-of-the-art techniques:
Self-supervised learning has emerged as a powerful paradigm for learning robust speech representations without emotion labels. Models like Wav2Vec 2.0 and HuBERT are pre-trained on large unlabeled speech corpora using masked prediction tasks. These pre-trained models can then be fine-tuned for SER, often outperforming models trained from scratch.
Training models to simultaneously predict emotions and other speech attributes (e.g., speaker identity, speech content) has shown to improve SER performance. This approach encourages the model to learn more generalizable features.
Adversarial training techniques have been used to improve the robustness and generalization of SER models. For example, training with adversarial examples or using domain adversarial neural networks for cross-corpus adaptation.
Graph-based approaches model the relations between different acoustic units or emotional states. Graph attention networks have shown promising results for SER, capturing complex dependencies in speech.
Combining acoustic features with other modalities like text, facial expressions, or physiological signals often leads to improved emotion recognition. Advanced fusion techniques like crossmodal attention have pushed the state-of-the-art in multimodal SER.
Continual learning approaches allow SER models to adapt to new speakers or emotional expressions without forgetting previously learned knowledge. This is crucial for real-world applications where the data distribution may shift over time.
As deep learning models become more complex, there's a growing focus on making them more interpretable. Techniques like Layer-wise Relevance Propagation (LRP) and SHAP (SHapley Additive exPlanations) values are being applied to understand which parts of the speech signal contribute most to emotion predictions.
Despite significant progress, several challenges remain in deep learning-based SER:
Corpus Mismatch: Models often struggle to generalize across different datasets due to variations in recording conditions, languages, and emotion definitions.
Cultural and Individual Differences: Emotion expression varies across cultures and individuals, making it challenging to develop universal SER models.
Continuous Emotion Recognition: Most work focuses on discrete emotion categories, but real-world emotions are often continuous and multi-dimensional.
Real-time Processing: Many deep learning models are computationally intensive, posing challenges for real-time SER applications.
Data Scarcity: High-quality labeled datasets for SER are still limited, especially for diverse languages and emotional expressions.
Bias and Fairness: Ensuring SER systems are unbiased across different demographic groups is an important ethical consideration.
Future research directions to address these challenges include:
Developing more robust and generalizable representations of emotional speech
Exploring few-shot and zero-shot learning for rapid adaptation to new speakers or emotions
Integrating contextual and background knowledge into SER models
Designing lightweight deep learning architectures for edge deployment
Creating larger, more diverse, and ethically sourced SER datasets
Developing benchmarks and evaluation protocols that better reflect real-world SER scenarios
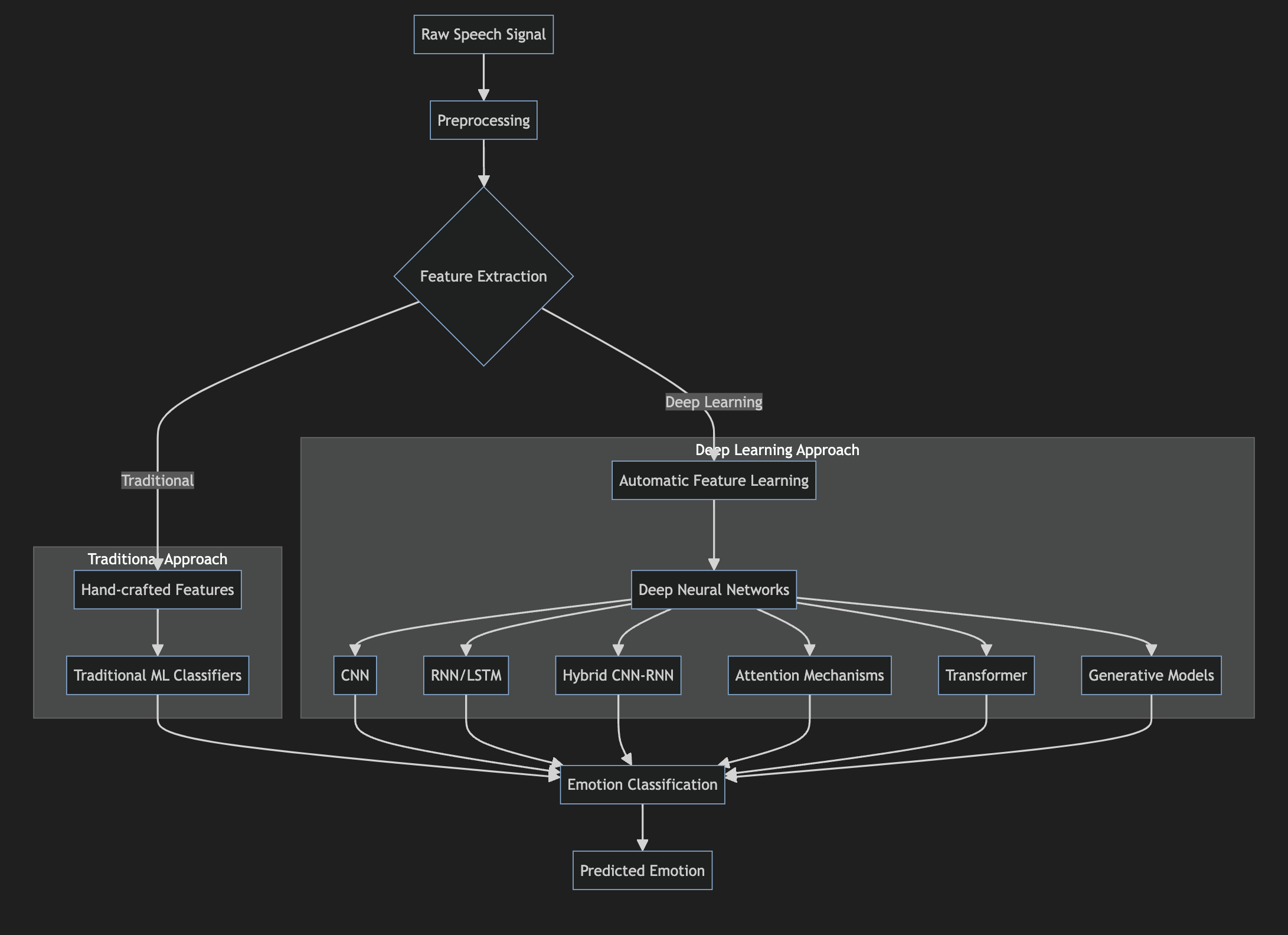
Deep learning has revolutionized speech emotion recognition, outperforming traditional approaches in most scenarios. From CNNs and RNNs to attention mechanisms and self-supervised learning, various deep learning techniques have pushed the boundaries of SER performance. State-of-the-art methods leverage large-scale pre-training, multimodal fusion, and advanced architectures to achieve impressive results.
However, challenges remain in developing robust, generalizable, and ethically sound SER systems. As research progresses, we can expect deep learning-based SER to play an increasingly important role in human-computer interaction, healthcare, and affective computing applications.
The field of SER is rapidly evolving, with new techniques and architectures constantly emerging. Researchers and practitioners should stay updated with the latest advancements while also considering the unique requirements and constraints of their specific SER applications. By combining the power of deep learning with domain expertise and ethical considerations, we can develop SER systems that truly understand and respond to human emotions.